MSA 아키텍쳐 구현을 위한 API 게이트웨이의 이해 #2
API 게이트웨이 기반의 디자인 패턴
API 게이트 웨이는 여러개의 엔드포인트를 설정하고, 각 엔드포인트 마다 메세지 흐름을 워크 플로우 엔진 설정을 통해서 API 에 대한 Mediation, Aggregation 설정을 할 수 있는 미들웨어 이다. 쉽게 말하면 설정과 프로그래밍이 가능한 툴일 뿐이다. 그래서, API 게이트 웨이를 도입한다고 게이트웨이가 재 역할을 하는 것이 아니라, 게이트웨이 를 이용하여 적절한 게이트 웨이 아키텍쳐를 설계해야 한다.
여기서는 API 게이트 웨이를 이용한 아키텍쳐 설계시 참고할 수 있는 디자인 패턴에 대해서 소개 한다.
※ 이 패턴들은 예전에 ESB 기반으로 SOA 프로젝트를 했을 때 사용했던 패턴으로 일반적인 이론이 아니라 실제 적용 및 검증을 거친 패턴이다.
다중 API 게이트웨이 아키텍쳐
API 게이트 웨이를 배포할때는 하나의 게이트웨이가 아니라 용도나 목적에 따라서 게이트 웨이를 분리하는 전략을 취할 수 있다. 몇가지 분리 패턴에 대해서 알아보도록 하자
내부 게이트웨이와 외부 게이트 웨이 엔드포인트 분리
가장 유용한 패턴중의 하나는 외부 서비스용 게이트웨이와 내부 서비스용 게이트웨이를 분리하는 방안이다. 물리적으로 게이트 웨이 자체를 두개로 나누는 방법도 있지만, 하나의 게이트웨이에서 엔드포인트를 내부용과 외부용으로 분리하는 방안이다.

<그림. 외부 및 내부 게이트웨이를 분리한 패턴>
같은 내부 API를 외부와 내부로 나눠서 서비스를 하되, 외부 엔드포인트에 대해서는 인증/인가 로직을 거치도록 한다.
내부 API 엔드포인트는 내부 IP를 가지도록 하고, 방화벽 안에서만 오픈하되 별도의 인증/인가 로직을 거치지 않고 내부 서버들이 API를 호출하는데 사용할 수 있도록 한다.
파일 업/다운로드 엔드포인트 분리
API 게이트웨이는 내부 구조는 쓰레드 풀 기반의 멀티 쓰레드나 또는 비동기 IO 기반의 싱글 쓰레드 모델을 사용한다.
쓰레드 풀 모델은 톰캣같은 WAS와 비슷한 모델로, 쓰레드 풀내의 하나의 쓰레드가 하나의 API 요청에 대해서 응답까지 모두 처리하는 모델로, API 요청이 들어오면 응답을 보낼때 까지 그 쓰레드는 해당 API 호출에 의해서 점유 된다 그래서, 이러한 모델의 API 게이트웨이는 일반적인 WAS와 마찬가지로 동시에 서비스 할 수 있는 트렌젝션 수가 쓰레드풀의 전체수밖에 되지 않는다.
싱글 쓰레드 모델은 비동기 IO 기반의 방식으로 멀티 쓰레드 모델에 비해서 많은 클라이언트를 처리할 수 있다.
(비동기 IO에 대한 개념은 http://bcho.tistory.com/881 을 참고하기 바란다. Node.js가 대표적인 비동기 IO 기반의 싱글 쓰레드 모델이다.)
파일 업로드나 다운로드와 같은 트렌젝션은 CPU는 많이 사용하지 않지만, 요청 처리에 시간이 많이 걸리는 작업이기 때문에, 쓰레드 풀 형태의 API 게이트 웨이 제품에서는 파일 업/다운로드에 쓰레드가 오랫동안 잡혀있기 때문에, 서비스를 할 수 있는 유휴 쓰레드 수가 적게 되고, 다른 일반 API 서비스에 영향을 줄 수 있다.
싱글 쓰레드 기반의 비동기 IO 게이트웨이의 경우에는 비동기 IO이기 때문에 파일 업/다운로드에는 다소 유리할 수 있지만, 네트워크 대역폭을 상당 부분 소모해버리기 때문에 마찬가지로 다른 API 서비스를 하는데 영향을 줄 수 있다.
그래서 이러한 파일 업/다운로드는 가급적이면 게이트 웨이를 거치지 않고 별도의 독립된 엔드포인트나 프록시를 사용하는 것이 좋은데, 다음은 별도의 프록시를 넣는 아키텍쳐 설계 방식의 예이다.

<그림. 파일 업/다운로드를 API 게이트웨이에서 분리해내는 방법>
1. API 클라이언트가 파일 서버에 API를 이용하여 파일 다운로드를 요청한다.
2. 파일 서버는 API에 대한 응답으로 파일을 바로 내리는 것이 아니라, 파일을 다운로드 받을 수 있는 URL과 함께, 임시 인증 토큰을 발급(현재 API 클라이언트에 IP 에만 유효하고, 특정시간 예를 들어 발급후 30분 이내만 사용이 가능한 토큰)하여, API 클라이언트에게 리턴한다.
3. API 클라이언트는 2에서 받은 URL로 임시 인증 토큰과 함께 파일 다운로드를 파일 다운로드 프로젝시를 통해서 요청한다.
4. 파일 다운로드 프록시는 임시 인증 토큰을 인증한 다음에, 파일 다운로드를 수행한다.
파일 다운로드 프록시는 일반적인 리버스 프록시 (HA Proxy, Nginx,Apache)등을 사용할 수 있으며 여기에 간단하게 다운로드용 임시 인증 토큰 로직을 넣으면 된다. 또는 아마존 클라우드의 CDN과 같은 서비스들도 임시 다운로드 토큰과 같은 서비스를 제공하기 때문에, CDN 사용시에도 유사하게 적용할 수 있는 아키텍쳐이다.
특수 목적 엔드포인트 분리
파일 업로드/다운로드 엔드 포인트를 분리한 것 처럼, 특수 목적의 엔드포인트는 별도의 API 게이트웨이로 분리해 내는 것이 좋다.
예를 들어 인증등이 없이 고속으로 많은 로그를 업로드 하는 엔드 포인트같은 경우, 부하량이 많기 때문에 다른 일반 API 엔드포인트에 부담을 주지 않기 위해서 분리 할 수 있다.
트렌젝션 ID 추적 패턴
MSA 아키텍쳐를 기반으로 하게 되면, 클라이언트에서 호출된, 하나의 API 요청은 API 게이트웨이와 여러개의 서버를 거쳐서 처리된 후에, 최종적으로 클라이언트에 전달된다.
만약에 중간에 에러가 났을 경우, 어떤 호출이 어떤 서버에서 에러가 났는지를 연결해서 판단해야 할 수 가 있어야 한다. 예를 들어 서버 A,B,C를 거쳐서 처리되는 호출의 경우 서버 C에서 에러가 났을때, 이 에러가 어떤 메세지에 의해서 에러가 난 것이고, 서버 A,B에서는 어떻게 처리되었는 찾으려면, 각 서버에서 나오는 로그를 해당 호출에 대한 것인지 묶을 수 있어야 한다.
하나의 API 호출을 트렌젝션이라고 정의하자, 그리고 각 트렌젝션에 ID를 부여하자. 그래서 API 호출시, HTTP Header에 이 트렌젝션 ID를 넣어서 서버간의 호출시에도 넘기면 하나의 트렌젝션을 구별할 수 있다.
여기에 추가적인 개념이 필요한데, 서버 A,B,C가 있을때, API 서버 B가 하나의 API 호출에서 동 두번 호출된다고 가정하자. 그러면 에러가 났을때 B 서버에 있는 로그중에, 이 에러가 첫번째 호출에 대한 에러인지, 두번째 호출에 대한 에러인지 어떻게 구분할까?
아래 그림을 서버 A->B로의 첫번째 호출과, 두번째 호출 모두 트렌젝션 ID가 txid:1로, 이 txid로는 구별이 불가하다.
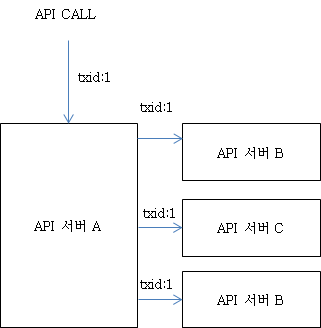
<그림. 단일 트렌젝션 ID를 사용했을때 문제>
그래서 이러한 문제를 해결하기 위해서는 글로벌 트렌젝션 ID(gtxid)와, 로컬 트렌젝션 ID (ltxid)의 개념을 도입할 수 있다.
API 호출을 하나의 트렌젝션으로 정의하면 이를 글로벌 트렌젝션 gtx라고 하고, 개별 서버에 대한 호출을 로컬 트렌젝션 ltx라고 한다. 이렇게 하면 아래 그림과 같이 하나의 API호출은 gtxid로 모두 연결될 수 있고 각 서버로의 호출은 ltxid로 구분될 수 있다
※ 사실 이 개념은 2개 이상의 데이타 베이스를 통한 분산 트렌젝션을 관리하기 위한 개념으로, 글로벌 트렌젝션과 로컬 트렌젝션의 개념을 사용하는데, 그 개념을 차용한것이다.

<그림. 글로벌 트렌젝션과 로컬 트렌젝션 개념을 이용한 API 트렌젝션 추적 방법>
이런 글로벌 트렌젝션과 로컬 트렌젝션 개념을 API 게이트웨이와 연동하여 아키텍쳐를 설계하면 다음과 같은 모양이된다.
다음 그림을 보자.

<그림, gtxid,ltxid를 이용한 API 트렌젝션 추적 아키텍쳐>
API 클라이언트는 API를 호출한다. API 클라이언트는 트렌젝션 ID에 대한 개념이 없다.
API 게이트 웨이에서, HTTP 헤더를 체크해서 x-gtxid (글로벌 트렌젝션 ID)가 없으면 신규 API 호출로 판단하고 트렌젝션 ID를 생성해서 HTTP 헤더에 채워 넣는다. 로컬 트렌젝션 ID로 1로 세팅한다.
2번에서, API 서버 A가 호출을 받으면, 서버 A는 헤더를 체크하여 ltxid를 체크하고, ltxid를 하나 더 더해서, 로그 출력에 사용한다. 같은 gtxid를 이용해서 같은 API호출임을 알 수 있고, ltxid가 다르기 때문에 해당 API서버로는 다른 호출임을 구별할 수 있다.
이런식으로 서버B,C도 동일한 gtxid를 가지지만, 다른 ltxid를 갖게 된다.
각 API 서버는 이 gtxid와 ltxid로 로그를 출력하고, 중앙에서 로그를 수집해서 보면, 만약에 에러가 발생한 경우, 그 에러가 발생한 gtxid로 검색을 하면, 어떤 어떤 서버를 거쳐서 트렌젝션이 수행되었고 어떤 서버의 몇번째 호출에서 에러가 발생하였는지 쉽게 판별이 가능하다.
작은 팁중에 하나로, 자바로 API 서버를 개발할 경우 서블릿 필터를 넣어서, gtxid가 헤더로 들어오면 이 gtxid를 TheadLocal 변수에 저장하고, ltxid는 새로 생성해서 ThreadLocal 변수에 저장 해놓으면, 로그를 출력할때 ThreadLocal 변수에 있는 gtxid와 ltxid를 꺼내서 같이 출력하면 번거롭게 클래스의 메서드등으로 gtxid와 ltxid를 넘길 필요가 없다. 그리고 로그 수집은 SL4J나 Log4J와 같은 일반 로깅 프레임웍을 이용해서 gtxid와 ltxid 기반으로 로그를 출력하고 출력된 로그를 파일이 아니라 logstash를 이용해서 모아서, ElasticSearch에 저장하고, Kibana로 대쉬 보드를 만들면, 손쉽게 트렌젝션 ID기반으로 API 호출 로그 추적이 가능해진다.
<참고>
출처: https://bcho.tistory.com/1006?category=431297
MSA 아키텍쳐 구현을 위한 API 게이트웨이의 이해 (API GATEWAY) #2 - API 게이트웨이 기반의 디자인 패
MSA 아키텍쳐 구현을 위한 API 게이트웨이의 이해 #2 API 게이트웨이 기반의 디자인 패턴 조대협 (http://bcho.tistory.com) API 게이트 웨이는 여러개의 엔드포인트를 설정하고, 각 엔드포인트 마다 메세지
bcho.tistory.com
'IT아키텍처 > MSA(MicroServiceArchitecture)' 카테고리의 다른 글
| [Kafka] #1 - 아파치 카프카(Apache Kafka)란 (0) | 2021.11.07 |
|---|---|
| 마이크로서비스 아키텍처 (MSA) (기본적인 개념과 우버의 적용 사례 ) (0) | 2021.10.10 |
| 배민 API GATEWAY – spring cloud zuul 적용기 (0) | 2021.10.10 |
| MSA 아키텍쳐 구현을 위한 API 게이트웨이의 이해 (API GATEWAY) (0) | 2021.10.03 |
| 대용량 웹서비스를 위한 마이크로 서비스 아키텍쳐 (0) | 2021.10.03 |