
데이터 파이프라인(Data Pipeline)을 구축할 때 가장 많이 고려되는 시스템 중 하나가 '카프카(Kafka)' 일 것이다. 아파치 카프카(Apache Kafka)는 링크드인(LinkedIn)에서 처음 개발된 분산 메시징 시스템이다.
2011년 오픈소스로 공개되었으며 이후 2012년 10월 아파치 인큐베이터를 종료했다. 현재 링크드인에서 카프카를 개발하던 제이 크렙스(Jay Kreps)를 비롯한 일부 엔지니어들이 'Confluent'라는 회사를 설립하여 카프카와 관련된 일을 하고 있다.
카프카라는 이름은 유명한 작가인 '프란츠 카프카(Franz Kafka)'에서 따왔다. (참조 : Quora)
I thought that since Kafka was a system optimized for writing using a writer's name would make sense. I had taken a lot of lit classes in college and liked Franz Kafka. Plus the name sounded cool for an open source project.
So basically there is not much of a relationship
제이 크렙스에 의하면, 쓰기에 최적화된 시스템이기 때문에 작가의 이름을 붙이는게 좋겠다고 생각하던 차에 대학에서 다양한 수업으로 접했던 프란츠 카프카의 이름을 따서 이름을 짓게되었고, 붙여보니 오픈소스 이름으로 괜찮은 이름이라 계속 사용하게 되었다고 한다. 카프카라는 이름이 아키텍처 혹은 구조와 크게 관련은 없다. 마치 하둡처럼?
Publish/Subscribe (펍/섭) 시스템
카프카는 기본적으로 Publish-Subscribe 모델을 구현한 분산 메시징 시스템이다. Publish-Subscribe 모델은 데이터를 만들어내는 프로듀서(Producer, 생산자), 소비하는 컨슈머(Consumer, 소비자) 그리고 이 둘 사이에서 중재자 역할을 하는 브로커(Broker)로 구성된 느슨한 결합(Loosely Coupled)의 시스템이다.
프로듀서는 브로커를 통해 메시지를 발행(Publish) 한다. 이 때 메시지를 전달할 대상을 명시하지는 않으며 관련 메시지를 구독(Subscribe) 할 컨슈머가 브로커에게 요청하여 가져가는 식이다. 마치 블로그 글을 작성하여 발행하면 블로그 글을 구독하는 독자들이 따로 읽어가는 형태를 생각하면 된다. (반대되는 개념으로는 글을 작성한 프로듀서가 구독하려는 컨슈머에게 직접 메일을 보내는 걸 생각하면 된다.)
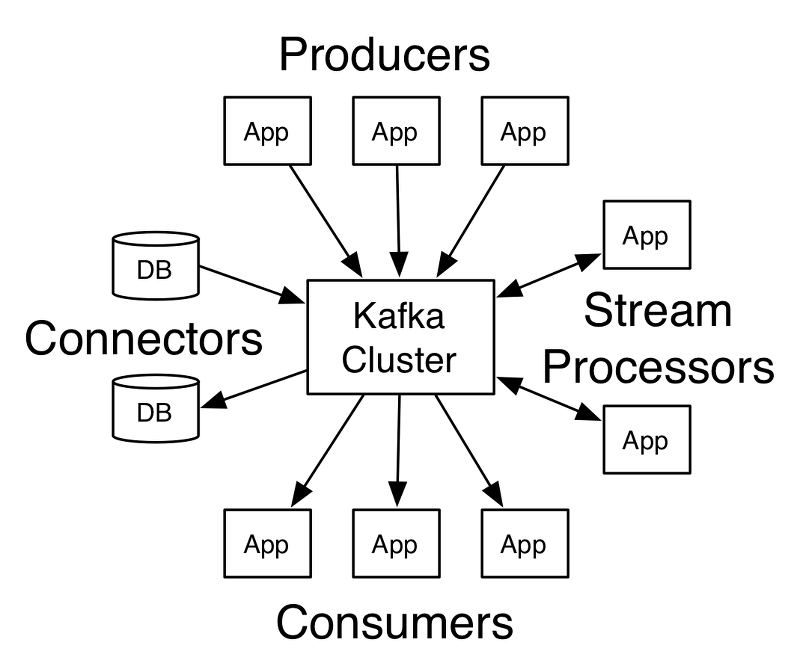
카프카 역시 카프카 클러스터로 메시지를 전송할 수 있는 프로듀서와 카프카로부터 메시지를 읽어 갈 수 있는 컨슈머 클라이언트 API를 제공한다. 그 밖에 데이터 통합을 위한 커넥터(Connector)와 스트림 처리를 위한 스트림즈(Streams) API도 있지만 이 역시 크게 보면 프로듀서와 컨슈머의 확장이라고 볼 수 있다.
카프카에서 프로듀서는 특정 토픽(Topic)으로 메시지를 발행할 수 있다. 컨슈머 역시 특정 토픽의 메시지를 읽어 갈 수 있다. 카프카에서 토픽은 프로듀서와 컨슈머가 만나는 지점이라고 생각할 수 있다. (블로그의 RSS 피드 정도로 생각하면 되겠다. 티스토리는 카프카에 해당하며 티스토리에 존재하는 블로그 하나하나는 각각 하나의 토픽으로 대응될 수 있다. 프로듀서에 해당하는 블로거는 특정 블로그에 글을 작성하여 발행할 수 있고, 컨슈머에 해당하는 독자는 특정 블로그의 RSS를 구독하는 것을 생각하면 된다.)

카프카는 수평적인 확장(scale horizontally, scale out)을 위해 클러스터를 구성한다. 카프카를 통해 유통되는 메시지가 늘어나면 카프카 브로커의 부담(Load)이 증가하게 되어 클러스터의 규모를 확장할 필요가 있다. 카프카는 여러 브로커들의 클러스터링을 위해 아파치 주키퍼(Apache ZooKeeper)를 사용한다. 주키퍼를 사용하여 브로커의 추가 및 장애 상황을 간단하게 대응할 수 있다.
카프카 클러스터 위에서 프로듀서가 전송한 메시지는 중복 저장(Replication 되어 장애상황에서도 고가용성(High Availability)을 보장하게 된다. 프로듀서가 메시지를 카프카 클러스터로 전송하면 브로커는 또 다른 브로커에게 프로듀서의 메시지를 중복해서 저장한다. 만약 한 브로커에 장애가 생기더라도 중복 저장된 복사본을 컨슈머에게 전달 할 수 있으므로 장애 상황에 대비(Fault-tolerant) 할 수 있다.
카프카의 특징
링크드인에서 카프카를 개발 할 당시에도 다양한 메시징 시스템이 존재했었다. 하지만 링크드인에서 처음 개발 될 때 기존 메시징 시스템과 비교하여 장점으로 내세울 수 있는 몇 가지 특징을 가지도록 설계되었다.
1) 다중 프로듀서, 다중 컨슈머
카프카의 토픽에 여러 프로듀서가 동시에 메시지를 전송할 수 있다. 마찬가지로 카프카 토픽의 메시지를 여러 컨슈머들이 동시에 읽어 갈 수 있다. 뿐만 아니라 하나의 프로듀서가 여러 토픽에 메시지를 전송할 수도 있으며, 하나의 컨슈머가 여러 토픽에서 메시지를 읽어 갈 수도 있다. 특히 하나의 메시지를 여러 컨슈머가 읽어 갈 수 있는 측면이 카프카의 큰 강점으로 작용한다.
이러한 다중 프로듀서, 다중 컨슈머의 지원을 통해 하나의 카프카 시스템을 통해 다양한 애플리케이션이 데이터를 주고 받을 수 있게 되었으며, 데이터의 생산자/소비자 관계도 유연하게 구성할 수 있게 되었다.
2) 파일시스템에 저장
전통적인 메시징 시스템은 프로듀서가 전송한 메시지를 브로커의 메모리 상에 존재하는 큐(Queue)에 유지한다. 이후 컨슈머가 메시지를 읽어가면 큐에서 메시지를 제거한다. 프로듀서가 생성한 메시지는 브로커를 통해 컨슈머에 의해 빠른 시간내에 소비될 것이라고 가정하고 만들어졌기 때문이다.
카프카는 프로듀서가 생성한 메시지를 브로커가 위치한 서버의 파일 시스템에 저장한다. 따라서 컨슈머는 프로듀서가 생성한 메시지를 바로바로 소비하지 않아도 되며 카프카가 메시지를 보존하고 있는 기간내에서는 언제든지 읽어 갈 수 있다.
이런 방식은 프로듀서와 컨슈머의 속도 차이가 있을 때 유용하다. 예를 들어 컨슈머 쪽에 장애가 생겼거나 순간적인 네트워크 트래픽 폭주로 처리가 늦어졌을 때 브로커의 동작에 큰 영향을 주지 않으면서 처리 속도를 따라갈 수 있게 해준다. 또 한 컨슈머들이 데이터를 모았다가 처리하는 배치(batch) 처리를 가능하게 해주며, 컨슈머 쪽에서 에러가 생겼을 때 이전에 읽었던 데이터를 다시 읽을 수 있게 해준다.
카프카 브로커가 파일 시스템에 저장한 메시지는 관리자에 의해 설정된 일정 보존 기간동안 사용가능하며 이후 브로커가 위치한 서버의 파일 시스템에서 삭제된다.
3) 확장성(Scalability)
카프카 클러스터는 운영중에 확장이 용이하도록 설계되었다. 데이터 파이프라인을 구축한 초창기 적은 수의 브로커들로 클러스터를 운영하다가 시스템 트래픽이 높아지면 브로커를 추가해서 클러스터를 확장할 수 있다. 이른바 수평적인 확장 (Horizontally Scale, Scale out) 이 쉽게 이뤄진다.
카프카 토픽에 메시지를 전송하는 프로듀서 역시 운영중에 얼마든지 증가시킬 수 있다. 카프카에서 메시지를 읽어가는 컨슈머의 경우 컨슈머 그룹으로 묶이며 컨슈머 그룹에 컨슈머를 추가할 수 있다. 컨슈머 그룹에 컨슈머가 추가되면 컨슈머의 파티션 소유권(Ownership)이 재분배되는 리밸런스 과정을 거쳐 컨슈머 그룹에 속한 컨슈머들이 고르게 파티션을 할당 받게 된다. 여튼 컨슈머 역시 운영 중에 무난하게 추가될 수 있다.
카프카 토픽은 내부에서 파티션(Partition)이라는 세분화된 단위로 나뉘어 저장되는데 토픽의 파티션 개수도 운영중에 추가할 수 있다.
이런 모든 확장 작업이 카프카 운영에 심각한 부담을 줄 정도는 아니며 쉽고 간편하게 이루어 질 수 있도록 설계되었다.
4) 고성능
카프카는 대용량 실시간 로그 처리에 특화되어 있다. 일반적인 범용 메시징 시스템이 지원하는 몇 가지 기능을 포기하면서 높은 처리량(Throughput)을 갖도록 설계되었다. 예를 들어 IBM Websphere MQ 같은 경우 복수의 큐(Queue)에 메시지들을 원자적(Atomically)으로 전달 할 수 있는 트랜잭션(Transaction) 기능을 제공한다. JMS의 경우 컨슈머가 메시지를 소비했는지 여부를 알 수 있는 기능도 제공한다.
하지만 범용 메시징 시스템이 제공하는 이런 기능은 링크드인에서 크게 중요한 기능으로 생각되지는 않았다. 오히려 이런 기능을 제공하기 위해 메시징 시스템 내부에서 복잡한 처리와 병목현상 등이 발생하여 성능을 최대로 끌어낼 수 없었다.
카프카는 이런 기능을 배제하고 뛰어난 처리량(Throughput)을 갖도록 설계되었다. 불필요한 기능을 제외하고 내부적으로 배치처리, 분산 처리와 같은 다양한 기법을 사용해 성능을 처리량을 최대로 끌어냈다. (덕분에 튜닝해야 할 파라미터가 많아지긴 했다)
카프카를 소개한 netDB 2011에 게재된 "Kafka: a Distributed Messaging System for Log Processing" 논문에서 카프카의 처리량을 다른 메시지 시스템과 비교했다. 비교 대상은 Apache ActiveMQ v5.4, RabbitMQ v2.4이며 카프카의 배치 사이즈를 1과 50으로 설정한 내용도 함께 비교했다. (RabbitMQ와 ActiveMQ의 경우 별도의 배치 처리를 지원하지 않는 듯 해서 batch 1로 설정된 것으로 간주하고 실험을 했다고 한다)
실험에는 2대의 리눅스 머신이 사용되었다. 리눅스 머신의 사양은 8개의 2GHz 코어와 16GB 메인 메모리, RAID 10으로 구성된 6장의 디스크로 구성되었다. 둘 중 하나는 브로커로 사용되었으며 나머지 하나는 컨슈머와 프로듀서로 사용되었다.

카프카를 소개한 논문이니 카프카가 잘 나왔겠지. 여튼 뛰어난 프로듀서 처리량 성능을 보인다.
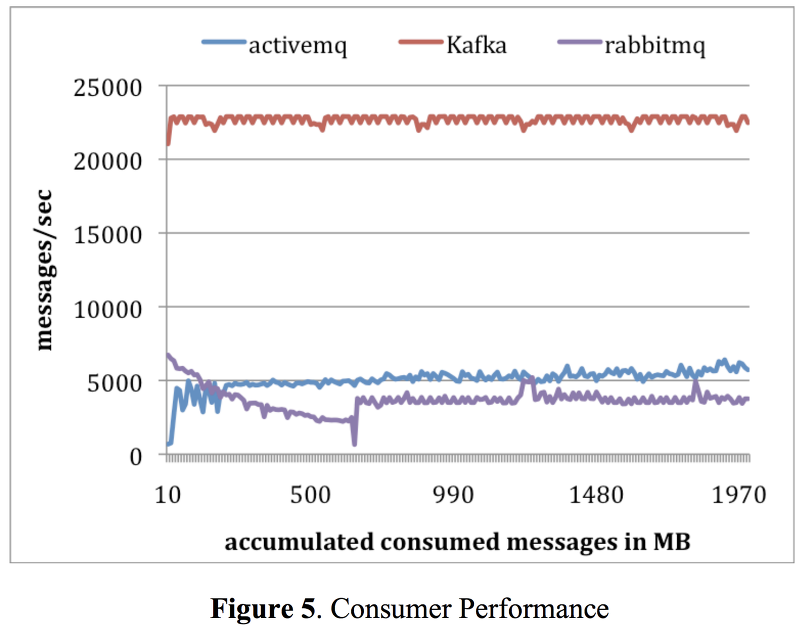
마찬가지로 뛰어난 컨슈머 처리량 성능을 보인다.
자세한 내용은 "Kafka: a Distributed Messaging System for Log Processing" 논문을 읽어보시길..
5) 컨슈머의 pull 방식
기존의 메시징 시스템의 경우 브로커가 컨슈머에게 데이터를 전달해주는 "Push 방식"을 채택한 경우가 많이 있다. 카프카는 컨슈머가 브로커에게서 메시지를 가져오는 "Pull 방식"을 채택했다.
Pull 방식을 사용하면 컨슈머의 처리량을 브로커가 고민할 필요가 없다. 컨슈머는 자신이 처리할 수 있는 만큼의 메시지만 브로커에게서 가져가면 되기 때문에 최적의 메시지처리 성능을 갖을 수 있다. 만일 컨슈머의 처리 속도가 프로듀서의 생산 속도보다 느리다면 컨슈머를 추가하여 처리량을 늘릴 수 있다. 또 한 메시지를 모았다가 한번에 처리할 수 있는 배치처리도 간단하게 구현할 수 있게 되었다.
카프카 살펴보기
1) 토픽(Topic)과 파티션(Partition) 그리고 세그먼트 파일(Segment File)
카프카에 전달되는 메시지 스트림의 추상화된 개념을 토픽(Topic)이라고 한다. 프로듀서는 메시지를 특정 토픽에 발행한다. 컨슈머는 특정 토픽에서 발행되는 메시지를 구독할 수 있다. 토픽은 프로듀서와 컨슈머가 만나는 접점이라고 생각하면 된다.
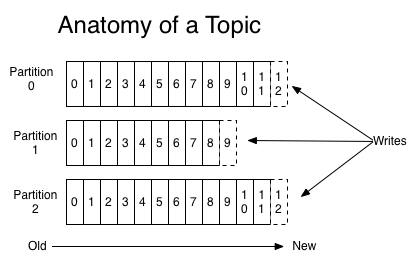
프로듀서가 메시지를 특정 토픽에 전송하면 카프카 클러스터는 토픽을 좀 더 세분화된 단위인 파티션(Partition)으로 나누어 관리한다. 기본적으로 프로듀서는 발행한 메시지가 어떤 파티션에 저장되는지 관여하지 않는다. (물론 메시지 키와 파티셔너를 이용하여 특정 파티션으로 메시지를 전송할 수 있도록 할 수도 있다.) 각 파티션은 카프카 클러스터를 구성하는 브로커들이 고루 나눠 갖는다. (카프카 클러스터의 브로커 중 한 녀석이 컨트롤러(Controller)가 되어 이 분배 과정을 담당한다. 컨트롤러는 카프카 클러스터의 반장 역할이라고 보면 된다)
특정 파티션으로 전달된 메시지에는 오프셋(Offset)이라고하는 숫자가 할당된다. 오프셋은 해당 파티션에서 몇 번째 메시지인지 알 수 있는 ID 같은 개념이라고 생각하면 된다. 오프셋을 이용해서 컨슈머가 메시지를 가져간다. 몇 번째 오프셋까지 읽었다, 몇 번째 오프셋부터 읽겠다는 요청을 할 수 있다. 오프셋은 파티션 내에서 유일한(Unique) 값을 갖는다.
카프카 브로커는 파티션에 저장된 메시지를 파일 시스템에 저장한다. 이 때 만들어지는 파일이 '세그먼트 파일(Segment File)'이다. 기본적으로 1GB까지 세그먼트 파일이 커지거나 일정 시간이 지나면 파일을 다시 만든다. 보존기간이 지난 메시지가 지워질 때 세그먼트 파일 단위로 지워진다.
2) 파티션의 복제(Replication)
카프카는 고가용성(High Availability)을 제공하기 위해 파티션 데이터의 복사본(Replication)을 유지할 수 있다. 몇 개의 복사본을 저장할 것인지는 리플리케이션 팩터(Replication Factor)로 저장할 수 있으며 토픽 별로 다르게 설정 할 수 있다.
만약 토픽의 리플리케이션 팩터를 N으로 설정하면 N개의 파티션 데이터 복사본이 생성되고 카프카 브로커가 겹치지 않게 나눠갔는다. N개의 복사본은 리플리카(Replica)라고 하며 N개중 1개의 리플리카가 리더(Leader)로 선정되어 클라이언트 요청을 담당한다. 나머지 N - 1 개의 리플리카는 팔로워(Follower)가 되어 리더의 변경사항을 따라가기만 한다. 프로듀서와 컨슈머의 쓰기, 읽기 요청은 리더 리플리카에만 전송되며 클라이언트 설정에 따라 팔로워들에게 전송되기까지 기다릴 수도 있고, 리더에게만 전송될 수도 있다.
리더의 변경사항을 잘 따라가면서 복사를 하는 팔로워는 ISR(In-Sync Replica)를 구성하며 리더 리플리카를 담당하는 브로커에 장애가 생겼을 때, ISR에 속한 리플리카가 새로운 리더로 선정되어 클라이언트 요청을 담당하게 된다. 만약 ISR에 있는 리플리카가 리더의 변경 사항을 미처 따라가지 못하면 ISR에서 빠지게 된다. (리더의 변경을 따라가지 못 한 팔로워가 새로운 리더가 되면 데이터가 유실되기 때문에..)
파티션의 리더와 팔로워는 다른 브로커에 할당해야 고가용성을 보장할 수 있다. 카프카 버전 0.10.0 부터는 랙(Rack)을 식별할 수 있는 정보도 명시할 수 있다. 즉, 데이터 센터에서 같은 랙에 있는 서버의 경우 전원이나 네트워크 스위치를 공유할 가능성이 있어 같이 장애가 발생할 수 있다. 리더와 팔로워 둘 중 하나는 장애에서 살아남아야 고가용성이 보장되기 때문에 다른 랙으로 할당할 수 있게 랙 정보를 입력할 수 있는 기능이 제공된다.
3) 프로듀서(Producer)와 컨슈머(Consumer), 컨슈머 그룹(Consumer Group)
카프카의 클라이언트는 기본적으로 프로듀서(Producer)와 컨슈머(Consumer)라는 두 가지 분류가 존재한다.

(출처 : Apache Documentation)
프로듀서(Producer)는 메시지를 생성하여 카프카에 전달하는 클라이언트를 의미한다. 프로듀서가 특정 토픽에 메시지를 전송하면 기본적으로 여러 파티션에 번갈아가며 전송되어 파티션을 골고루 사용하게 된다. 전송 순서가 중요한 메시지의 경우 메시지에 키(Key)값을 할당하고 이 키를 기반으로 특정 파티션에 전송되도록 파티셔너를 작성할 수도 있다.
프로듀서에서 유의해야 할 점은 서로 다른 파티션으로 전송된 메시지의 소비 순서는 보장되지 않는다는 것이다. 첫 번째 메시지가 0번 파티션으로 전송되고 두 번째 메시지가 1번 파티션으로 전송되었을 때, 컨슈머가 1번 파티션에 있는 두 번째 메시지를 먼저 소비할 수도 있다. 만약 메시지의 처리 순서가 중요한 경우라면 메시지 키와 파티셔너를 이용해 두 개의 메시지가 같은 파티션으로 전송되도록 추가적인 작업이 필요하다. 즉, 카프카로 전송된 메시지는 같은 파티션일 경우에만 순서가 보장된다.
(출처 : Apache Documentation)
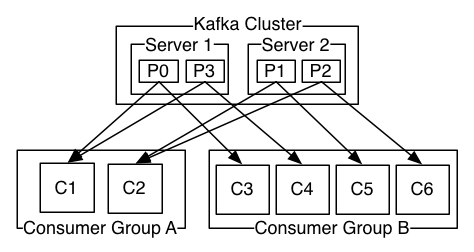
컨슈머(Consumer)는 메시지를 카프카로부터 읽어가는 클라이언트다. 카프의 컨슈머는 컨슈머 그룹(Consumer Group)을 형성한다. 카프카의 토픽은 컨슈머 그룹 단위로 구독되어진다. 토픽의 파티션은 컨슈머 그룹 당 오로지 하나의 컨슈머의 소비만 소비될 수 있다. 파티션과 컨슈머의 이런 연결을 소유권(Ownership)이라고 부른다. 다시말해서 같은 컨슈머 그룹에 속한 컨슈머들이 동시에 동일한 파티션에서 메시지를 읽어갈 수 없다.
파티션과 컨슈머의 Ownership 관계는 브로커와 컨슈머의 구성이 변경되지 않는 이상 계속 유진된다. 즉, 컨슈머 그룹에 컨슈머가 추가 혹은 제거 된 경우 컨슈머 그룹내에서 파티션의 소유권을 재분배하는 리밸런싱(Rebalancing) 과정이 실행된다. 리밸런싱을 통해 컨슈머 그룹 내의 컨슈머들이 파티션을 고르게 할당받아 소비할 수 있게 된다. 카프카 클러스터에 브로커가 추가/제거 되는 경우 전체 컨슈머 그룹들에서 리밸런싱이 발생한다.
컨슈머 그룹의 컨슈머 수가 토픽의 파티션 수보다 많은 경우, 파티션 개수만큼의 컨슈머만 동작하며 나머지 잉여 컨슈머들은 놀게 된다. 따라서 파티션 개수와 컨슈머 그룹내 컨슈머 개수의 절절한 조정이 필요하다.
컨슈머 그룹은 각 파티션에 대해 오프셋(Offset) 값을 할당받는다. 이 오프셋은 파티션에 저장된 메시지에 할당된 오프셋 값으로 컨슈머 그룹이 해당 파티션에서 어디까지 읽었는지를 의미한다. 따라서 특정 컨슈머 그룹에 컨슈머가 추가, 제거되어 리밸런싱이 일어났을 때 다른 컨슈머가 파티션을 할당받아도 내 컨슈머 그룹이 어디까지 읽었는지 기록이 유지되기 때문에 이어서 처리할 수 있게 된다.
컨슈머가 카프카로부터 메시지를 읽어서 처리한 다음 '여기까지 읽어서 처리했어요'라고 컨슈머 그룹에 할당된 오프셋을 변경하는 작업을 오프셋 커밋(Commit) 이라고 한다. 오프셋 커밋을 잘 처리하지 않으면 카프카 클라이언트를 사용하는 애플리케이션에서 메시지 누락이 발생하거나 불필요한 중복 처리가 발생할 수 있으므로 잘 이해하고 사용해야한다.
4) Kafka와 Filesystem
카프카로 전송된 메시지는 카프카 내부에서 세그먼트 파일 형태로 저장된다. 파일을 파일시스템에 기록하여 메시지의 영속성(Persistence)을 얻는다. 즉 나중에 다시 특정 메시지를 소비하고 싶을 때 파일 시스템에 저장된 메시지를 읽어서 컨슈머에게 전송할 수 있는 것이다.
파일 시스템을 사용할 때, 일반적으로 Durability는 보장이 되지만 속도가 느리다는 단점이 있다. 하지만 세대가 거듭되면서 운영체제(OS)와 파일 시스템의 하드디스크 최적화가 진행되었고, 하드디스크의 물리적인 구성에 따라 순차읽기(Sequential read)와 미리 읽기 (Read Ahead) 등의 최적화를 통해 제법 빠르게 사용할 수 있게 되었다. (Kafka 문서를 보면, ACM Queue에 게제된 글에서 하드디스크의 순차읽기 성능이 메모리의 랜덤 읽기 성능보다 빠르다는 내용을 찾아볼 수 있다. 물론 메모리의 순차읽기가 더 빠르며 하드디스크의 랜덤 읽기는 참혹할 정도로 느리다)
{kind=link}
카프카는 파일 시스템에 세그먼트 파일을 쓰는 동작에서 별도의 버퍼 캐시를 구현하는 대신 운영체제의 페이지 캐시를 사용했다. 운영체제는 사용하지 않는 메모리를 파일 시스템의 페이지 캐시로 사용하며, 사용자가 요청하지 않아도 미리 읽기(Read Ahead) 동작을 통해 앞으로 읽을 가능성이 있는 뒤쪽 내용을 미리 메모리를 읽어들이는 최적화를 진행한다. 또 카프카 내부에서 버퍼캐시를 운영하지 않기 때문에 JVM에 의해 발생할 수 있는 GC(Garbage Collection) 오버헤드도 줄인다. 또 한 브로커를 재시작하는 경우에도 페이지 캐시는 커널 영역에 남아있으므로 웜업되어 있는 상태로 서비스를 시작할 수 있게 된다.
5) 효율성(Efficiency)
카프카는 효율성(Efficiency)을 극대화하기 위해 매우 노력했다.
우선 메시지의 크기가 작은 경우 네트워크 오버헤드가 상대적으로 커질 수 있는 상황을 해소하기위해 메시지 셋(Message Set)단위로 메시지를 모아서 처리하는 배치(Batch) 처리를 가능하도록 기능을 제공했다. 메시지를 모아서 처리하는 배치를 이용해서 네트워크 오버헤드도 줄일 수 있고, 디스크에 최대한 연속적으로 메시지를 쓸 수 있는 순차처리의 장점을 얻을 수도 있다.
또 한, 디스크와 네트워크 채널 사이에 데이터 전송시 발생할 수 있는 오버헤드를 줄이기 위해 sendfile 시스템 호출을 이용하는 제로카피(Zero-copy) 기법을 사용하여 성능향상을 도모했다. (관련 글 : [Linux] 제로카피(Zero-copy))
아파치 카프카는 손쉽게 데이터 파이프라인을 구축할 수 있는 오픈소스 프로젝트다. 손쉽게 사용할 수 있지만 제대로 사용하고 튜닝하려면 내부 동작을 잘 알아야 한다. 관련된 내부 동작 공부를 심도있게 해야할 필요가 있을 것 같다.
References
- Kafka: a Distributed Messaging System for Log Processing, netDB 11
'IT아키텍처 > MSA(MicroServiceArchitecture)' 카테고리의 다른 글
| 아파치 카프카(Apache Kafka)란? (0) | 2021.11.08 |
|---|---|
| 메시지 큐(Message Queue, MQ)란? (0) | 2021.11.08 |
| 마이크로서비스 아키텍처 (MSA) (기본적인 개념과 우버의 적용 사례 ) (0) | 2021.10.10 |
| 배민 API GATEWAY – spring cloud zuul 적용기 (0) | 2021.10.10 |
| MSA 아키텍쳐 구현을 위한 API 게이트웨이의 이해 (API GATEWAY) #2 (0) | 2021.10.03 |